# 改hostname sudo vi /etc/hostname # 改網路設定 sudo vi /etc/sysconfig/network-scripts/ifcfg-eno16777736 # 配置玩各台電腦,並透過`sudo service network restart`重啟網路服務後 # 生成新的SSH key ssh-keygen -t rsa -P "" # 在sparkServer0,把他的ssh key傳到各台電腦去 tee run.sh << "EOF" #!/bin/bash for hostname in `cat $HADOOP_CONF_DIR/slaves`; do ssh-copy-id -i ~/.ssh/id_rsa.pub $hostname done EOF
啟動hadoop server / zookeeper server / hbase server /
1 2 3 4 5 6 7 8 9 10
# 執行hadoop的namenode format hdfs namenode -format # 啟動hadoop server start-dfs.sh & start-yarn.sh # 啟動zookeeper server zkServer.sh start ssh tester@cassSpark2 "zkServer.sh start" ssh tester@cassSpark3 "zkServer.sh start" # 啟動hbase server start-hbase.sh
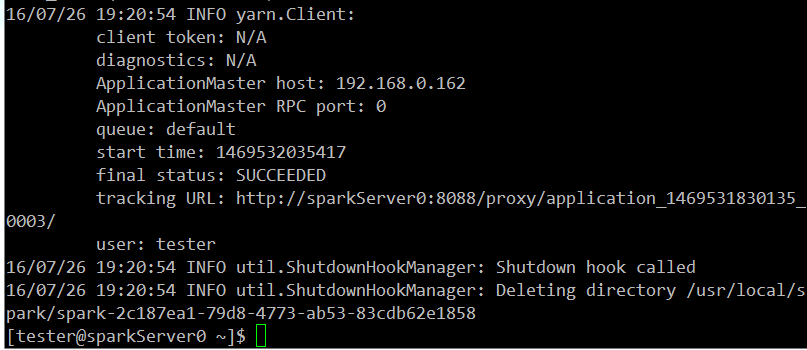
測試 i. Hadoop MapReduce例子 - pi estimation
1 2 3 4
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.4.jar pi 10 1000 # output會像下面這樣 # Job Finished in 2.413 seconds # Estimated value of Pi is 3.14800000000000000000
ii. zookeeper 再來是測試看看zookeeper是否有部署成功,先輸入zkCli.sh -server cassSpark1:2181,cassSpark2:2181,cassSpark3:2181可以登錄到zookeeper的server上,如果是正常運作會看到下面的訊息:
SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/usr/local/hbase/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/usr/local/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] HBase Shell; enter 'help<RETURN>'for list of supported commands. Type "exit<RETURN>" to leave the HBase Shell Version 1.1.5, r239b80456118175b340b2e562a5568b5c744252e, Sun May 8 20:29:26 PDT 2016
# 塞資料 put 'testData','row1','cf:a','value1' # 0 row(s) in 0.1170 seconds put 'testData','row2','cf:b','value2' # 0 row(s) in 0.0130 seconds put 'testData','row3','cf:c','value3' # 0 row(s) in 0.0240 seconds
# 列出所有表 list # TABLE # testData # 1 row(s) in 0.0040 seconds # # => ["testData"]
# 創表SQL cat $PHOENIX_HOME/examples/STOCK_SYMBOL.sql # -- creates stock table with single row # CREATE TABLE IF NOT EXISTS STOCK_SYMBOL (SYMBOL VARCHAR NOT NULL PRIMARY KEY, COMPANY VARCHAR); # UPSERT INTO STOCK_SYMBOL VALUES ('CRM','SalesForce.com'); # SELECT * FROM STOCK_SYMBOL;
# create table psql.py sparkServer0:2181 $PHOENIX_HOME/examples/STOCK_SYMBOL.sql # SLF4J: Class path contains multiple SLF4J bindings. # SLF4J: Found binding in [jar:file:/usr/local/phoenix/lib/phoenix-4.7.0-HBase-1.1-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] # SLF4J: Found binding in [jar:file:/usr/local/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] # SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. # 16/07/24 23:25:53 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable # no rows upserted # Time: 1.246 sec(s) # # 1 row upserted # Time: 0.102 sec(s) # # SYMBOL COMPANY # ---------------------------------------- ---------------------------------------- # CRM SalesForce.com # Time: 0.028 sec(s)
# insert data psql.py -t STOCK_SYMBOL sparkServer0:2181 $PHOENIX_HOME/examples/STOCK_SYMBOL.csv # SLF4J: Class path contains multiple SLF4J bindings. # SLF4J: Found binding in [jar:file:/usr/local/phoenix/lib/phoenix-4.7.0-HBase-1.1-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] # SLF4J: Found binding in [jar:file:/usr/local/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] # SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. # 16/07/24 23:32:14 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable # csv columns from database. # CSV Upsert complete. 9 rows upserted # Time: 0.074 sec(s)
# 查詢資料 sqlline.py sparkServer0:2181 # Setting property: [incremental, false] # Setting property: [isolation, TRANSACTION_READ_COMMITTED] # issuing: !connect jdbc:phoenix:sparkServer0:2181 none none org.apache.phoenix.jdbc.PhoenixDriver # Connecting to jdbc:phoenix:sparkServer0:2181 # SLF4J: Class path contains multiple SLF4J bindings. # SLF4J: Found binding in [jar:file:/usr/local/phoenix/lib/phoenix-4.7.0-HBase-1.1-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] # SLF4J: Found binding in [jar:file:/usr/local/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] # SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. # 16/07/24 23:34:17 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable # Connected to: Phoenix (version 4.7) # Driver: PhoenixEmbeddedDriver (version 4.7) # Autocommit status: true # Transaction isolation: TRANSACTION_READ_COMMITTED # Building list of tables and columns for tab-completion (set fastconnect to true to skip)... # 85/85 (100%) Done # Done # sqlline version 1.1.8