本篇主要介紹如何在Windows環境下編譯GPU版本的mxnet
需要的components有:
- Visual Studio 2015 Update 3以上
- OpenBLAS或是Intel MKL 2017 (我這用Intel MKL 2017)
- CUDA Toolkit 8.0 下載安裝
- cuDNN 需要登入會員
- CMake 下載Windows win64-x64 ZIP,然後解壓縮
- OpenCV 下載最新版本的3.2.0 win pack,然後解壓縮
為了說明方便,假設在D槽開一個資料夾,叫做mxnet
先把整個mxnet repository clone到D:\mxnet\mxnet,然後開啟CMake\bin\cmake-gui.exe
(可能開啟會錯誤,先檢查一下bin下面所有檔案,右鍵內容,右下角是否有解除鎖定的按鈕)
然後where is the source code選D:\mxnet\mxnet,然後按下configure
他會先問你要用什麼編譯,選VS 2015 Win64,然後問是否要開一個新資料夾for build,按下Yes繼續
接下來會說找不到BLAS,那我這裡要用MKL,所以BLAS那個選項選MKL,然後再按一次configure
(如果要用OpenBLAS就直接把OpenBLAS_INCLUDE_DIR跟OpenBLAS_LIB修改上去即可)
然後會跳出INTEL_ROOT, MKL_INCLUDE, MKL_ROOT這三個選項,設定好相對的路徑後按下configure
接下來會問OpenCV的位置,一樣設定路徑之後再按一次configure,最後應該會看到下面這樣的配置
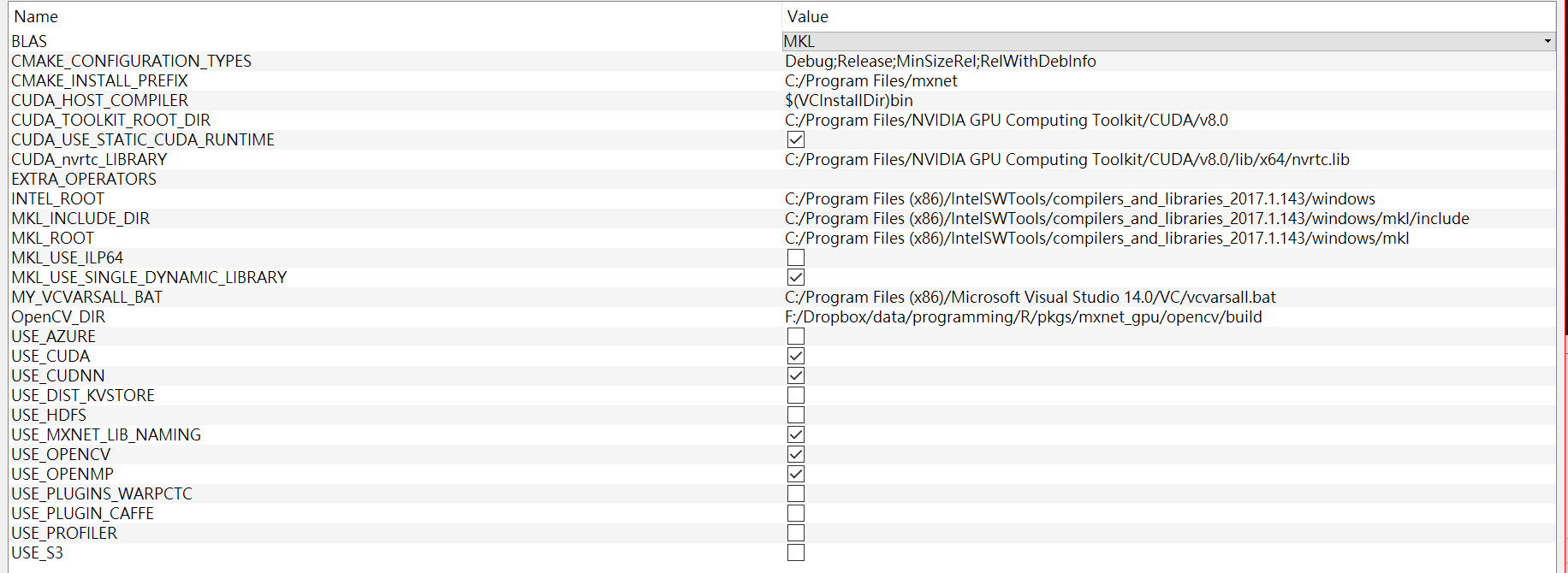
然後再按一次configure不會跳出任何錯誤後,按下Generate,下方出現Generate Done之後
按下Open Project就會打開Visual Studio 2015,接下來點方案'mxnet'右鍵選擇建置方案
大概等個一小時之後就build完了
再來是安裝R套件,請先在D:\mxnet\mxnet\R-package\inst建一個libs資料夾,裡面再建一個x64資料夾
然後把D:\mxnet\mxnet\Debug\libmxnet.dll, CUDA路徑下bin的cublas64_80.dll, cudart64_80.dll,
cudnn64_5.dll, curand64_80.dll跟nvrtc64_80.dll以及opencv路徑下的bin\opencv_ffmpeg320_64.dll,
x64\vc14\bin\opencv_world320.dll跟x64\vc14\bin\opencv_world320d.dll複製到剛剛建立的R-package\inst\x64裡面
然後把INTEL ROOT下面的redist\intel64_win\mkl\mkl_rt.dll, redist\intel64_win\mkl\mkl_intel_thread.dll,
redist\intel64_win\mkl\mkl_avx.dll, redist\intel64_win\mkl\mkl_vml_avx.dll (不同電腦用的指令集不同,不一定是用這兩個DLL)
以及redist\intel64_win\mkl\libimalloc.dll放到R目錄下的bin\x64裡面
(要抓哪些DLL是根據dependencywalker找的,請查看dependencywalker,不過MKL部分是我自己試出來的)
再來是建立一個R-package\inst\include的資料夾,把D:\mxnet\mxnet\mshadow\mshadow, D:\mxnet\mxnet\dmlc-core\include\dmlc,
D:\mxnet\mxnet\nnvm\include\nnvm, D:\mxnet\mxnet\include\mxnet複製到R-package\inst\include
跑下面這個script
1
2
3
4
5
6
7
| echo import(Rcpp) > R-package/NAMESPACE
echo import(methods) >> R-package/NAMESPACE
R CMD INSTALL R-package
Rscript -e "require(mxnet); mxnet:::mxnet.export(\"R-package\")"
rm -rf R-package/NAMESPACE
Rscript -e "require(roxygen2); roxygen2::roxygenise(\"R-package\")"
R CMD INSTALL R-package
|
安裝之後就到D:\mxnet\mxnet\example\image-classification試跑看看train_mnist.R --network mlp --gpus 0
或是簡單測一下下面的script:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| require(mlbench)
require(mxnet)
data(Sonar, package = "mlbench")
Sonar[,61] <- as.numeric(Sonar[,61])-1
train.ind <- c(1:50, 100:150)
train.x <- data.matrix(Sonar[train.ind, 1:60])
train.y <- Sonar[train.ind, 61]
test.x <- data.matrix(Sonar[-train.ind, 1:60])
test.y <- Sonar[-train.ind, 61]
mx.set.seed(0)
model <- mx.mlp(train.x, train.y, hidden_node=10, out_node=2, out_activation="softmax",
num.round = 20, array.batch.size=15, learning.rate=0.07, momentum=0.9,
eval.metric=mx.metric.accuracy, device = mx.gpu(0))
model <- mx.mlp(train.x, train.y, hidden_node=10, out_node=2, out_activation="softmax",
num.round = 20, array.batch.size=15, learning.rate=0.07, momentum=0.9,
eval.metric=mx.metric.accuracy, device = lapply(0:1, mx.cpu))
preds <- predict(model, test.x, mx.gpu(0))
pred.label = max.col(t(preds))-1
table(pred.label, test.y)
|
至於Python套件部分,到python的子資料夾,執行python setup.py install
然後把上面所說的mkl_rt.dll, mkl_core.dll, mkl_intel_thread.dll, pencv_ffmpeg320_64.dll,
opencv_world320.dll以及opencv_world320d.dll放到Python的根目錄,然後到D:\mxnet\mxnet\example\image-classification
試跑下面的命令驗證看看GPU是否正常安裝:
1
| python train_mnist.py --network mlp --gpus 0
|
最後用python稍微看一下Performance差異:
Performance of prebuilt GPU:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| # GPU
INFO:root:Epoch[0] Batch [100] Speed: 49999.99 samples/sec Train-accuracy=0.783261
INFO:root:Epoch[0] Batch [200] Speed: 49999.99 samples/sec Train-accuracy=0.909062
INFO:root:Epoch[0] Batch [300] Speed: 50393.66 samples/sec Train-accuracy=0.931875
INFO:root:Epoch[0] Batch [400] Speed: 49999.99 samples/sec Train-accuracy=0.934375
INFO:root:Epoch[0] Batch [500] Speed: 51200.00 samples/sec Train-accuracy=0.935781
INFO:root:Epoch[0] Batch [600] Speed: 49999.99 samples/sec Train-accuracy=0.950469
INFO:root:Epoch[0] Batch [700] Speed: 49612.42 samples/sec Train-accuracy=0.950469
INFO:root:Epoch[0] Batch [800] Speed: 50000.08 samples/sec Train-accuracy=0.949531
INFO:root:Epoch[0] Batch [900] Speed: 49612.33 samples/sec Train-accuracy=0.957812
INFO:root:Epoch[0] Train-accuracy=0.957348
INFO:root:Epoch[0] Time cost=1.629
INFO:root:Epoch[0] Validation-accuracy=0.959793
# CPU
INFO:root:Epoch[0] Batch [100] Speed: 42666.71 samples/sec Train-accuracy=0.790687
INFO:root:Epoch[0] Batch [200] Speed: 42105.21 samples/sec Train-accuracy=0.906250
INFO:root:Epoch[0] Batch [300] Speed: 42384.10 samples/sec Train-accuracy=0.928438
INFO:root:Epoch[0] Batch [400] Speed: 41830.03 samples/sec Train-accuracy=0.942656
INFO:root:Epoch[0] Batch [500] Speed: 41025.67 samples/sec Train-accuracy=0.946250
INFO:root:Epoch[0] Batch [600] Speed: 42105.28 samples/sec Train-accuracy=0.942344
INFO:root:Epoch[0] Batch [700] Speed: 42105.28 samples/sec Train-accuracy=0.950469
INFO:root:Epoch[0] Batch [800] Speed: 41025.60 samples/sec Train-accuracy=0.955937
INFO:root:Epoch[0] Batch [900] Speed: 42384.10 samples/sec Train-accuracy=0.958594
INFO:root:Epoch[0] Train-accuracy=0.953125
INFO:root:Epoch[0] Time cost=1.853
INFO:root:Epoch[0] Validation-accuracy=0.962082
|
Performance of built by myself (RelWithDebInfo):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| # GPU
INFO:root:Epoch[0] Batch [100] Speed: 52459.03 samples/sec Train-accuracy=0.781405
INFO:root:Epoch[0] Batch [200] Speed: 54700.81 samples/sec Train-accuracy=0.907656
INFO:root:Epoch[0] Batch [300] Speed: 56637.21 samples/sec Train-accuracy=0.925000
INFO:root:Epoch[0] Batch [400] Speed: 55172.44 samples/sec Train-accuracy=0.940156
INFO:root:Epoch[0] Batch [500] Speed: 51200.00 samples/sec Train-accuracy=0.941406
INFO:root:Epoch[0] Batch [600] Speed: 55652.17 samples/sec Train-accuracy=0.944063
INFO:root:Epoch[0] Batch [700] Speed: 54237.27 samples/sec Train-accuracy=0.952812
INFO:root:Epoch[0] Batch [800] Speed: 55172.44 samples/sec Train-accuracy=0.954844
INFO:root:Epoch[0] Batch [900] Speed: 55172.33 samples/sec Train-accuracy=0.960313
INFO:root:Epoch[0] Train-accuracy=0.949324
INFO:root:Epoch[0] Time cost=1.493
INFO:root:Epoch[0] Validation-accuracy=0.952130
# CPU
INFO:root:Epoch[0] Batch [100] Speed: 42105.28 samples/sec Train-accuracy=0.790842
INFO:root:Epoch[0] Batch [200] Speed: 41830.03 samples/sec Train-accuracy=0.907813
INFO:root:Epoch[0] Batch [300] Speed: 41558.43 samples/sec Train-accuracy=0.927188
INFO:root:Epoch[0] Batch [400] Speed: 42105.28 samples/sec Train-accuracy=0.934844
INFO:root:Epoch[0] Batch [500] Speed: 42105.28 samples/sec Train-accuracy=0.944531
INFO:root:Epoch[0] Batch [600] Speed: 42384.10 samples/sec Train-accuracy=0.944063
INFO:root:Epoch[0] Batch [700] Speed: 42384.10 samples/sec Train-accuracy=0.950469
INFO:root:Epoch[0] Batch [800] Speed: 42105.28 samples/sec Train-accuracy=0.957812
INFO:root:Epoch[0] Batch [900] Speed: 42384.10 samples/sec Train-accuracy=0.957812
INFO:root:Epoch[0] Train-accuracy=0.959882
INFO:root:Epoch[0] Time cost=1.789
INFO:root:Epoch[0] Validation-accuracy=0.962082
|
Performance of built by myself (Release with Intel C++ 2017, /O3 flags):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| # GPU
INFO:root:Epoch[0] Batch [100] Speed: 60377.39 samples/sec Train-accuracy=0.791151
INFO:root:Epoch[0] Batch [200] Speed: 59259.24 samples/sec Train-accuracy=0.913438
INFO:root:Epoch[0] Batch [300] Speed: 60952.37 samples/sec Train-accuracy=0.927031
INFO:root:Epoch[0] Batch [400] Speed: 57657.63 samples/sec Train-accuracy=0.938906
INFO:root:Epoch[0] Batch [500] Speed: 61538.41 samples/sec Train-accuracy=0.943594
INFO:root:Epoch[0] Batch [600] Speed: 60377.39 samples/sec Train-accuracy=0.945000
INFO:root:Epoch[0] Batch [700] Speed: 61538.55 samples/sec Train-accuracy=0.945781
INFO:root:Epoch[0] Batch [800] Speed: 62135.82 samples/sec Train-accuracy=0.952500
INFO:root:Epoch[0] Batch [900] Speed: 60952.37 samples/sec Train-accuracy=0.957031
INFO:root:Epoch[0] Train-accuracy=0.960726
INFO:root:Epoch[0] Time cost=1.386
INFO:root:Epoch[0] Validation-accuracy=0.962878
# CPU
INFO:root:Epoch[0] Batch [100] Speed: 52458.92 samples/sec Train-accuracy=0.786665
INFO:root:Epoch[0] Batch [200] Speed: 52892.64 samples/sec Train-accuracy=0.911094
INFO:root:Epoch[0] Batch [300] Speed: 52892.54 samples/sec Train-accuracy=0.930781
INFO:root:Epoch[0] Batch [400] Speed: 52032.56 samples/sec Train-accuracy=0.933594
INFO:root:Epoch[0] Batch [500] Speed: 53333.38 samples/sec Train-accuracy=0.941094
INFO:root:Epoch[0] Batch [600] Speed: 52892.64 samples/sec Train-accuracy=0.945781
INFO:root:Epoch[0] Batch [700] Speed: 52892.54 samples/sec Train-accuracy=0.950156
INFO:root:Epoch[0] Batch [800] Speed: 53333.28 samples/sec Train-accuracy=0.957031
INFO:root:Epoch[0] Batch [900] Speed: 53333.38 samples/sec Train-accuracy=0.958125
INFO:root:Epoch[0] Train-accuracy=0.953125
INFO:root:Epoch[0] Time cost=1.506
INFO:root:Epoch[0] Validation-accuracy=0.962480
|
可以看出我們自己用Intel C++ 2017 加上 O3 optimization的速度
在GPU方面比prebuilt每秒多了一千張,CPU部分則多了將近10000張
The performace gain worths your time!!