SQL on Hadoop不外乎Apache Drill, Hive, Hive on Tez, Phoenix,
Cloudera Impala (正在孵化為Apache專案), Presto,
Pivotal HAWQ, IBM BigSQL, Apache Tajo, Apache Kylin等
在這麼多選擇中,我選擇用Drill,以下闡述我的原因
Drill是一套SQL on Hadoop的解決方案
一個Schema-free的data model,這意思代表說不在受限於data model限制而無法查詢
但是他不能用index,所以在有些查詢上會比有schema的data model來的慢
儘管如此,Drill在query的表現仍然相當優秀,勝過Hive with MapReduce, Hive on Tez,
Spark SQL, Presto,跟Impala互有上下 (reference 1, reference 2)
不過問題來了,Drill要base什麼去建立? hdfs? hbase? hive? 還是其他nosql的架構?
這個就depends on每個人的需求了,因為我需要一個Loader去同步在Oracle的資料
而這loader最簡單的方式就是使用Spark SQL去做(因為Drill沒辦法直接讀寫hive, hbase等資料庫)
所以這裡我採用hive當做表格儲存的位置,能讓Spark SQL直接做table的存寫
而且Drill直接搜尋hive的速度相當快,不需要透過hive下的engine(mapredure, tez or spark)去處理
我原本傾向使用有schema的hbase跟hive,可以直接透過Spark SQL去存讀資料
但是又想到我需要一個Loader去同步在Oracle的資料,不過Drill無法提供直接使用DataFrame存寫的功能
做了一點功課之後,決定直接使用HDFS存JSON檔案
在Spark SQL可以透過JDBC接口直接使用Spark SQL去處理資料再存新的json回去
- 下載檔案並部署
1 | curl -v -j -k -L http://apache.stu.edu.tw/drill/drill-1.8.0/apache-drill-1.8.0.tar.gz -o apache-drill-1.8.0.tar.gz |
- 配置
使用vi /usr/local/bigdata/drill/conf/drill-override.conf去configure Drill
1 | drill.exec: { |
如果記憶體不多的話建議下面配置:
1 | tee -a /usr/local/bigdata/drill/conf/drill-env.sh << "EOF" |
複製到各台node
1 | scp -r /usr/local/bigdata/drill tester@cassSpark2:/usr/local/bigdata |
使用/usr/local/bigdata/drill/bin/drillbit.sh start去啟動Drill
就可以用http://192.168.0.121:8047/連到Drill的web UI了
可以再Storage Page看到dfs的Option,按下Update即可更新(更新下面的值即可):
1 | "connection": "hdfs://hc1", |
按下Update,然後Close
再來是上傳一些資料吧
1 | tee ~/test_df.json << "EOF" |
上傳到hdfs去:
1 | hdfs dfs -mkdir /drill |
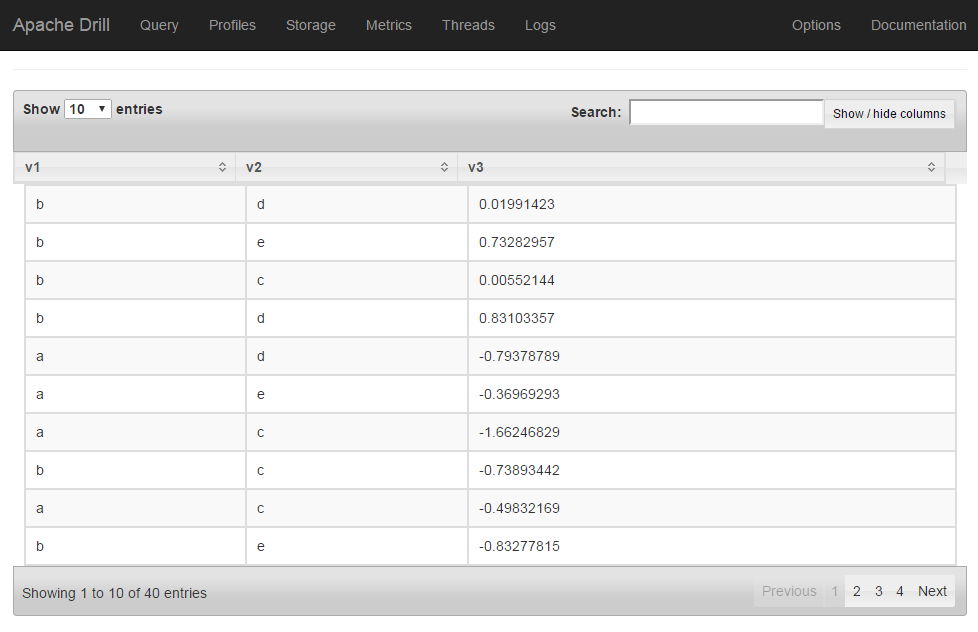
執行下面的SQL可以得到下圖的結果
1 | SELECT * FROM dfs.`/drill/test_df.json`; |
執行下面的SQL可以得到下圖的結果
1 | SELECT * FROM dfs.`/drill/test_widecol.json`; |

使用SQuirreL SQL Client透過JDBC去操作Drill
先點擊左邊的Driver按鈕,然後按下左上角藍色的+去新增Driver
其中Example URL填jdbc:drill:zk=cassSpark1:2181
Extra Class Path新增Drill binary tar裡面jars/jdbc-driver/drill-jdbc-all-1.8.0.jar
Driver就可以選org.apache.drill.jdbc.Driver了,如同下圖的設定

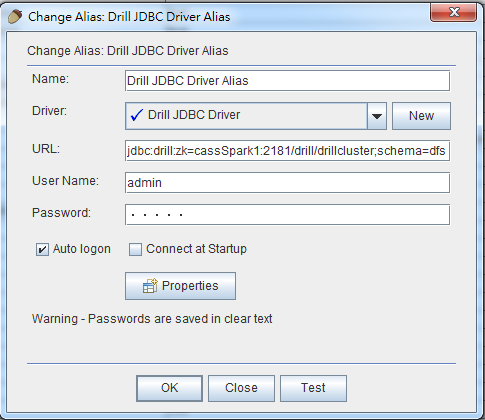
接著點擊左邊的Alias,一樣按下藍色的+去新增,其中URL的填法如下:
1 | jdbc:drill:zk=<zookeeper_quorum>/<drill_directory_in_zookeeper>/<cluster_ID>;schema=<schema_to_use_as_default> |
像是我的是jdbc:drill:zk=cassSpark1:2181/drill/drillcluster;schema=dfs
cassSpark1:2181是我的zookeeper地址,drillcluster是我在conf裡面設定的cluster name
使用的預設schema就dfs (請看Drill網頁UI裡面的Storage那頁),設定會如下圖:
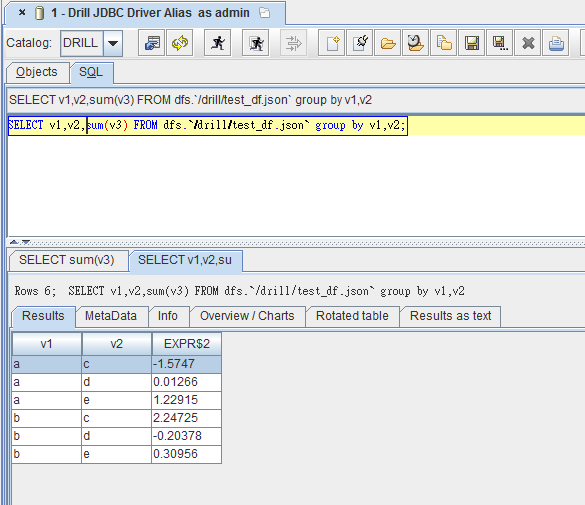
然後就可以連線了!如下圖:

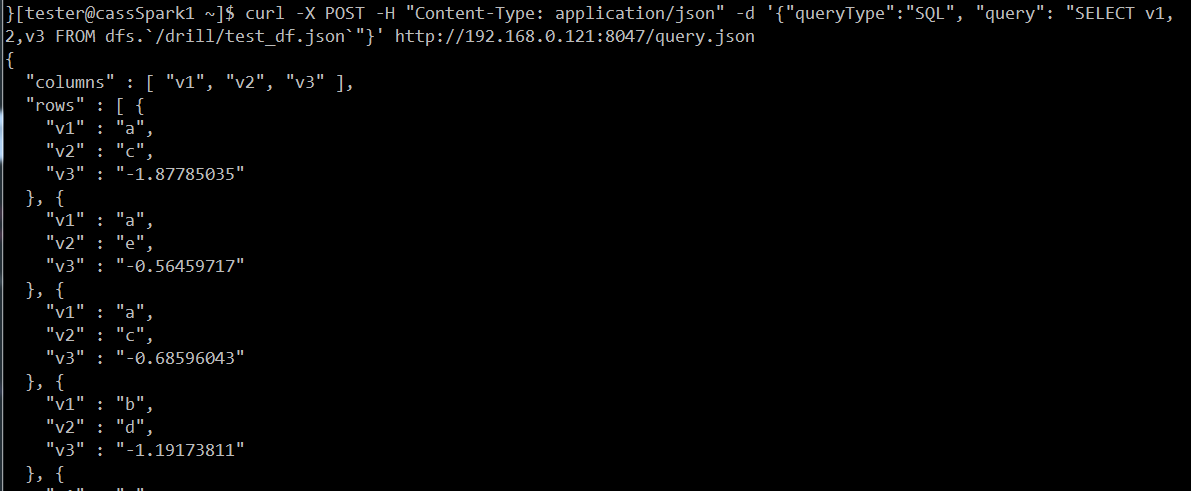
再來是Drill的REST接口
這裡分別用linux的curl指令跟R httr套件的POST去做:

1 | library(httr) |
另外,也可以用jdbc去連Oracle,先從Oracle官方網站下載到ojdbc7.jar
將ojdbc7.jar放到/usr/local/bigdata/drill/lib/3party裡面,然後重開drill (記得是每一台都要放)
(如果有用我之前Spark在Oracle的配置,可以直接下cp $SPARK_HOME/extraClass/ojdbc7.jar /usr/local/bigdata/drill/jars/3rdparty/)
然後在web UI的Storage增加一個New Storage Plugin,叫做oracle:
1 | { |
就可以使用select * from oracle.<user_name>.<table_name>去做查詢了
最後附上supervisor的config
1 | sudo tee -a /etc/supervisor/supervisord.conf << "EOF" |