前一篇的Apache Drill效能方面極佳
唯一可惜的點是不能直接存寫hive, hbase
但是如果只需要用到讀取資料
不做insert, update的話,Drill無疑是最佳的方案
這篇主要介紹怎麼建立Hive,Hive的建立相當麻煩
以前建立過一次,就不想在建立它,只是沒想到還是得用它
Hive有三種建立模式:
- localhost derby
- localhost mysql
- remote mysql
以前是直接走localhost mysql,這次則採用remote mysql的方式建立
這樣的好處是,全部的cluster都共用一個metastore,不需要再各台都建立mysql
mysql也可以用其他資料庫代替,如Oracle, PostgreSQL以及MS SQL Server
不過在centos中最簡單取得的就是Mysql,而我這使用的是Oracle MySQL community server
請到下面網址去下載Red Hat Enterprise Linux 7 / Oracle Linux 7 (x86, 64-bit), RPM Bundle:
http://dev.mysql.com/downloads/mysql/
並在 http://dev.mysql.com/downloads/connector/j/ 下載mysql的jdbc連線用的jar檔
- 安裝
1 | # 開始部署 |
hive的配置項目:
1 | <property> |
配置完hive之後,就可以開始啟動了
1 | # 新增hive所需的目錄 |
- 測試:
1 | tee ~/test_df.csv << "EOF" |
1 | CREATE TABLE test_df (v1 STRING, v2 STRING, v3 DOUBLE) |
附上成功執行畫面:

可以看到它是透過hadoop的mapreduce去做的,執行時間是23.925秒
- 與Apache Drill共舞
先修改Storage的hive,改成下方這樣:
1 | { |
到query去執行下方的查詢:
1 | select v1,v2,avg(v3) from test_df group by v1,v2; |
可以在Profile那裏看到執行的細節:
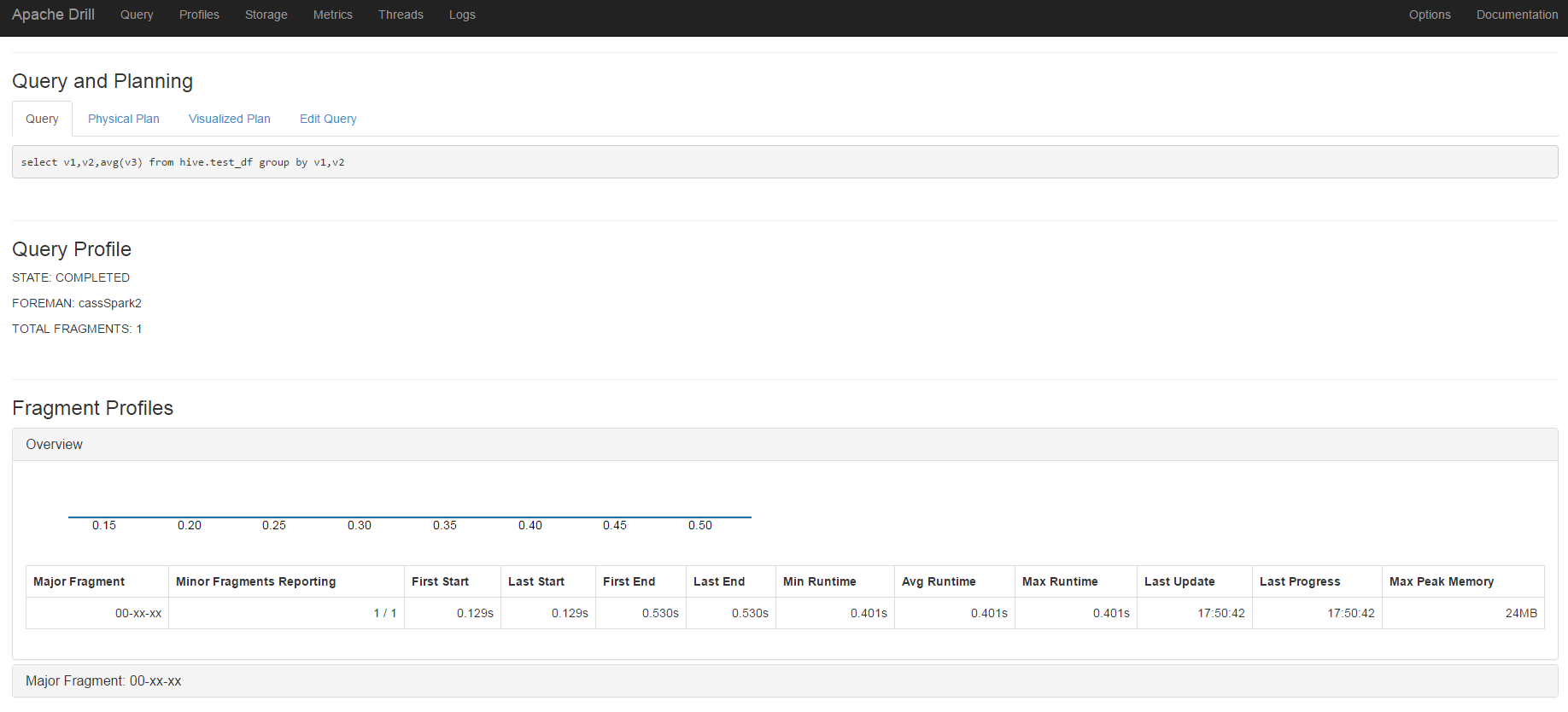
全部執行時間只有0.530s,整整比hive的mapreduce快上45倍
最後,也測試看看R直接用Drill的REST方式去query到hive的結果
1 | library(httr) |
- 將mysql納入supervisord
執行下面的指令即可
1 | sudo systemctl stop mysqld |